Dismantling and modeling cocaine trafficking networks
Data insights on four cocaine smuggling networks
Criminal networks are a major and ubiquitous problem in modern societies. However, effective and general approaches to interrupt their functioning are still an open problem. In this post, I will apply a method of network dismantling to four cocaine smuggling networks. These networks are the result of operations from 2006 to 2009 and include countries such as Brazil, Colombia, Mexico, Spain, and Uruguay. Additionally, by the end of this post, I will suggest that these networks can be modeled using an extension of the Barabási-Albert model.
The United Nations Office on Drugs and Crime (UNODC) defines drug trafficking as “a global illicit trade involving the cultivation, manufacture, distribution and sale of substances which are subject to drug prohibition laws”. A 2021 report indicates that the amount of cocaine seized globally reached record levels in 2019, with the majority of cocaine continuing to be seized in the Americas. Despite immense and increasing efforts to interrupt these activities, counterdrug interdictions appear to be making the situation worse. Drug trafficking networks are flexible, fluid structures and can respond instantly to attacks. For example, it has been suggested that some networks can become even more efficient after targeted attacks.
In terms of network dismantling, a naive approach for attacking criminal networks is to target the most connected people (those with a high degree of centrality). But realistically, this does not work. It turns out that the cost of targeting these individuals can be substantially greater than attacking other criminals in the network. Moreover, in times of conflict, these central positions are often replaceable by other criminals. The resilience of a criminal network also depends on its level of redundancy, that is, how easily the individuals are replaceable. These characteristics make dismantling criminal networks an arduous task.
Several approaches have been proposed for the purpose of dismantling networks. These approaches are divided into either link or node removal. Here you can see a comparative analysis of the main methods currently used in scientific research. In particular, I will be applying, on four Cocaine Smuggling Networks, a dismantling method proposed in a PNAS paper (Generalized Network Dismantling). The advantage of this method is that it takes into account the cost of attacking the vertices. The cost of removing a vertex is its degree centrality and the algorithm finds a set of nodes whose removal results in the fragmentation of the network at minimal overall cost.
To perform the dismantling analysis, I adapted Petter Holme’s implementation. Thanks to him, the method proposed in the paper was converted from C++ to Python 2. I then converted it to Python 3 and applied it to the networks.
Ultimately, my main goals in this post are
- Present the Generalized Network Dismantling (GND) method by examining its effectiveness and comparing the costs when the simplest dismantling approach (removing the highest degree vertices) is applied.
- Suggest that cocaine smuggling networks can be modeled via an extension of the Barabási-Albert model.
Cocaine trafficking groups
The dataset contains information collected during police investigations of four groups involved in cocaine trafficking. These groups form networks in which the vertices represent the individuals and the links indicate their communications. The networks are shown below, with the size of each node proportional to its degree.
Operation MAMBO: The investigation started in 2006 and involved Colombian citizens that were introducing 50 kg of cocaine to be adulterated and distributed in Madrid (Spain). Ultimately, the group was involved in smuggling cocaine from Colombia through Brazil and Uruguay to be distributed in Spain. This is a typical Spanish middle cocaine group acting as wholesale supplier between a South American importer group and retailers in Madrid.
Mambo network: 31 vertices and 58 edges.
Operation ACERO: This investigation started in 2007 and involved a smaller family-based group. The group was composed mainly of members of a same family and was led by a female. They distributed cocaine in Madrid (Spain) that was provided to them by other groups based in a northwest region of the country, one of the most active areas in the provision of cocaine from the countries of origin. The group also had their own procedures to launder money.
Acero network: 25 vertices and 37 edges.
Operation JAKE: In 2008, the group investigated was operating as a wholesale supplier and retail distributor of cocaine and heroin in a large distribution zone located in Madrid (Spain), where gypsy clans traditionally carry out similar activities. The group was in charge of acquiring, manipulating and selling the drugs in the gypsy quarter.
Jake network: 38 vertices and 50 edges.
Operation JUANES: In 2009, the police investigation detected a group involved in the smuggling of cocaine from Mexico to be distributed in Madrid (Spain). In this case, the group operated in close cooperation with another organization that was laundering the illegal income from drug distribution from this and other groups. The cocaine traffickers earned an estimated EUR 60 million.
Juanes network: 51 vertices and 93 edges.
In terms of network metrics, these networks exhibit low density (i.e, they are sparse), negative assortativity (which means that high degree nodes have a slight tendency to connect to low degree nodes), and relatively low average clustering. Since these networks are relatively small in size, an analysis of the degree distribution would not be so informative. However, a brief preliminary calculation using Powerlaw’s Python package showed that power law distributions were in better agreement compared to the exponential distributions. The community structure analysis was also not very helpful. Although I used Infomap to color the nodes according to each module, I was unable to find community structures using the Bayesian SBM. Below are some of the main metrics I calculated for these networks.
Click to show the density
smuggling_networks_density
0.125 # Mambo
0.123 # Acero
0.071 # Jake
0.073 # Juanes
Click to show the assortativity
smuggling_networks_assortativity
-0.088 # Mambo
-0.160 # Acero
-0.173 # Jake
-0.081 # Juanes
Click to show average clustering
smuggling_networks_average_clustering
0.442 # Mambo
0.268 # Acero
0.110 # Jake
0.364 # Juanes
Click to show network efficiency
smuggling_networks_global_efficiency
0.473 # Mambo
0.481 # Acero
0.420 # Jake
0.373 # Juanes
Click to show average shortest path
smuggling_networks_average_shortest_path
2.473 # Mambo
2.413 # Acero
2.705 # Jake
3.308 # Juanes
Click to show the pseudo network diameter
smuggling_networks_global_efficiency
4.0 # Mambo
5.0 # Acero
4.0 # Jake
7.0 # Juanes
Network dismantling
The following video demonstrates a simple dismantling simulation of the Juanes network. For a better visualization, I have applied the basic approach based on degree. The purpose of this video is to show the network changing while the high degree nodes are being removed.
In the following figures, I show the (normalized) size of the largest connected component (LCC) as a function of the number of nodes removed. In each figure, pale pink represents the degree-based approach and pale blue represents the GND method1. Since Petter Holme’s implementation comes with a randomness to make the output independent of the labeling of nodes, I have used average values. Moreover, in order to have a baseline, the black line shows the average of a random node removal approach and the shaded region represents a standard deviation band. The insets present the cumulative cost (i.e, the sum of the degrees) of removing the vertices.
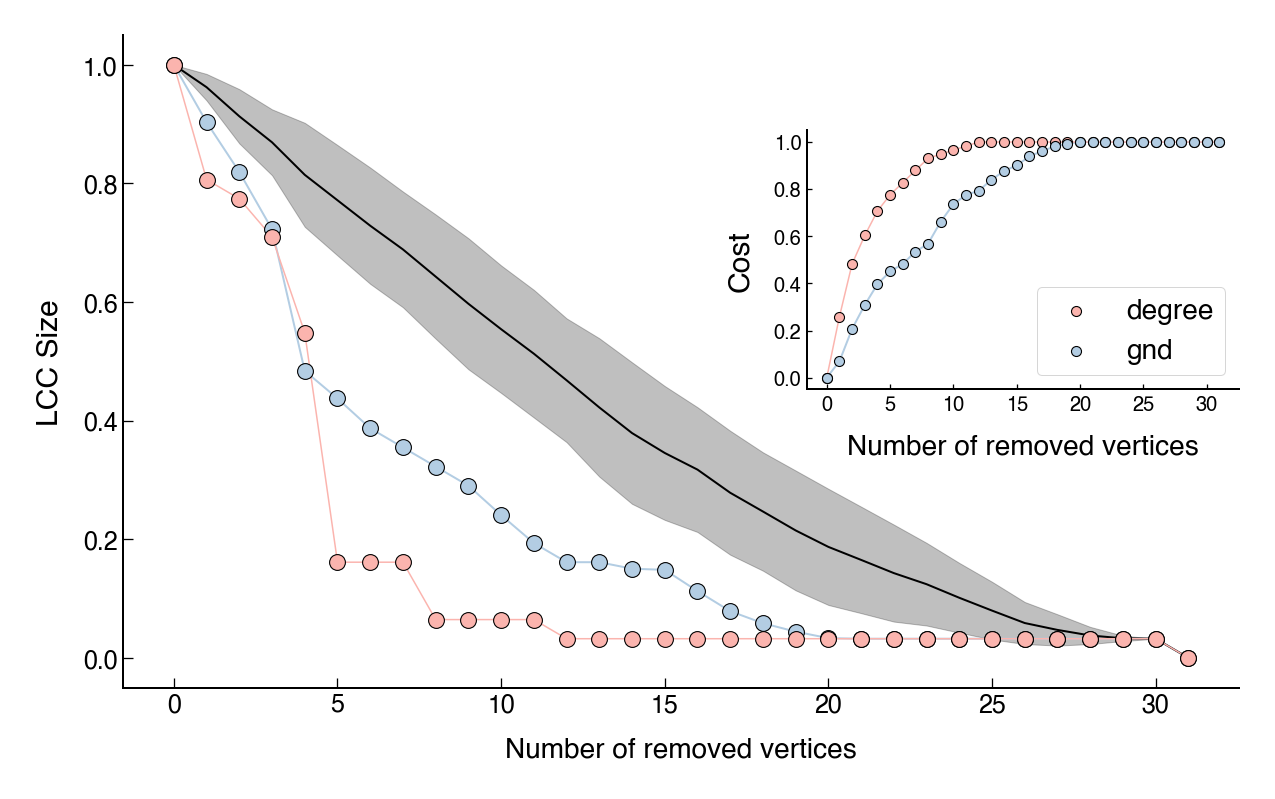
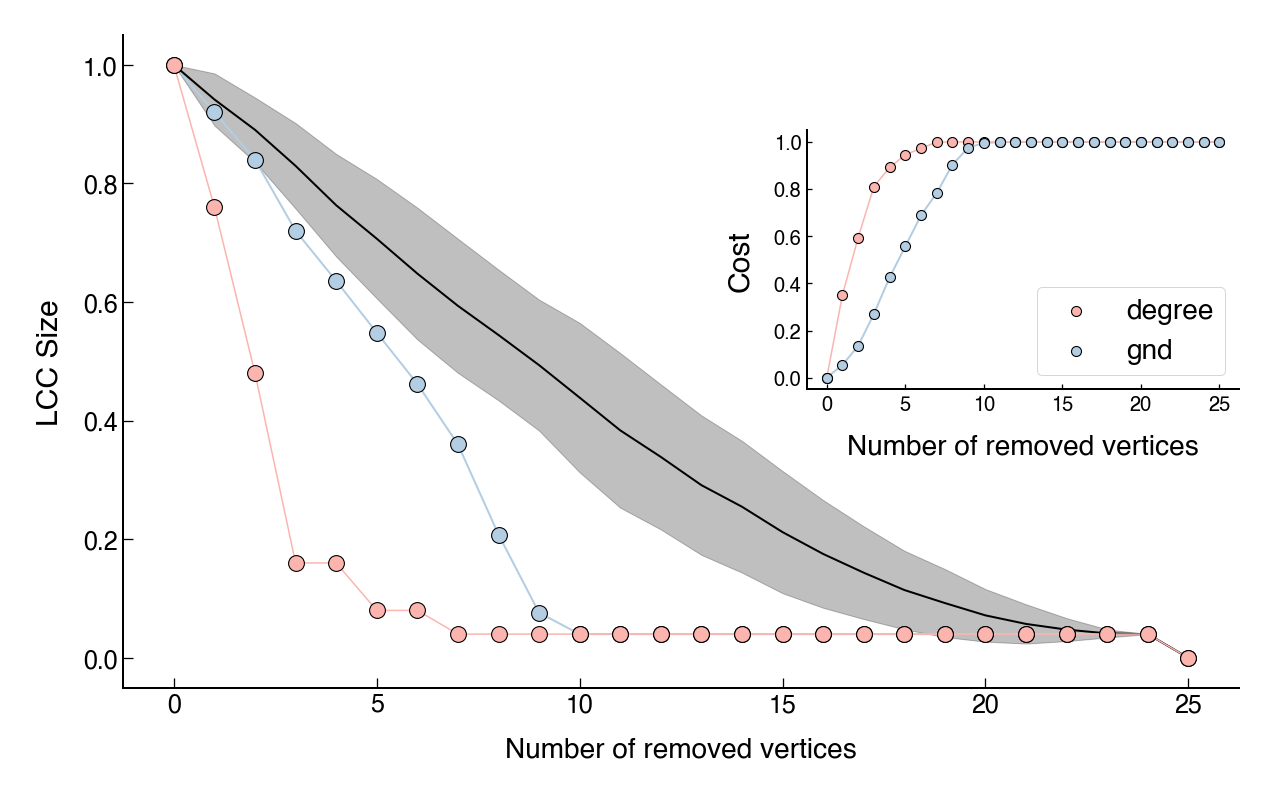
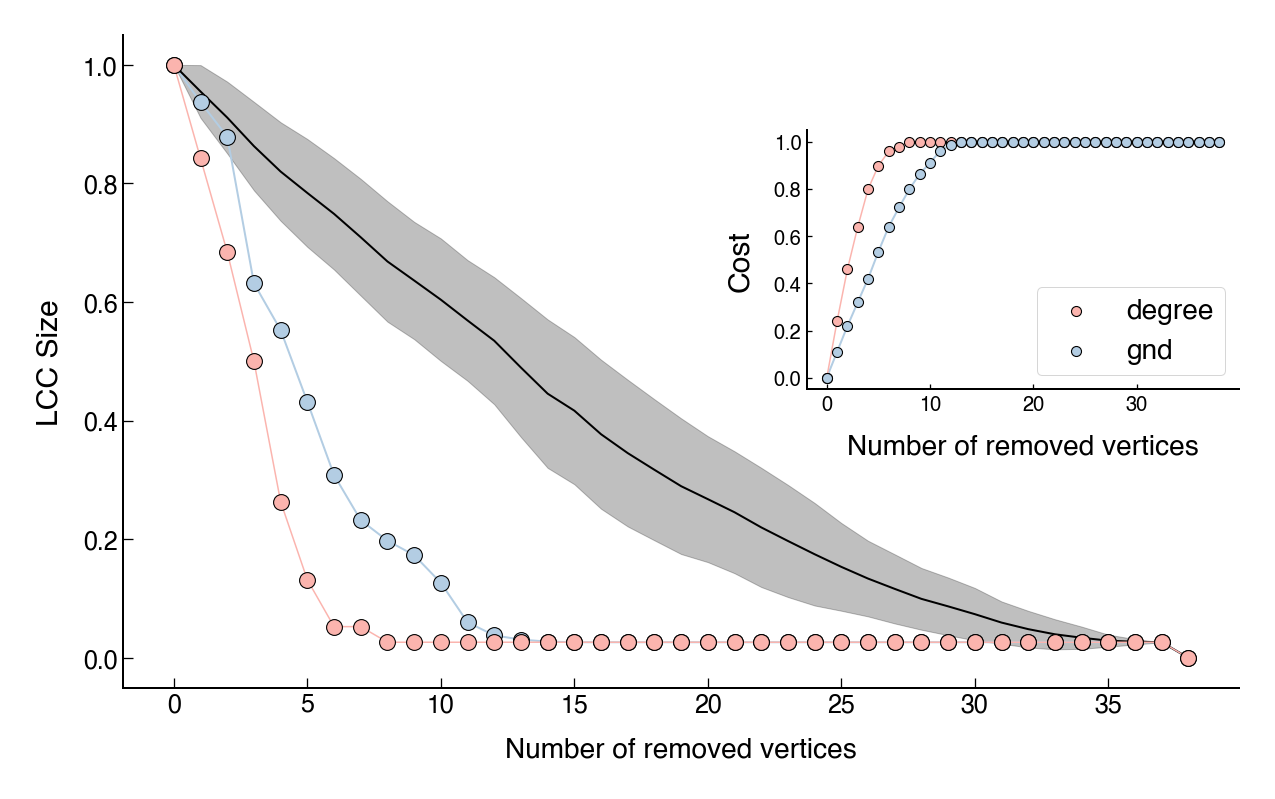
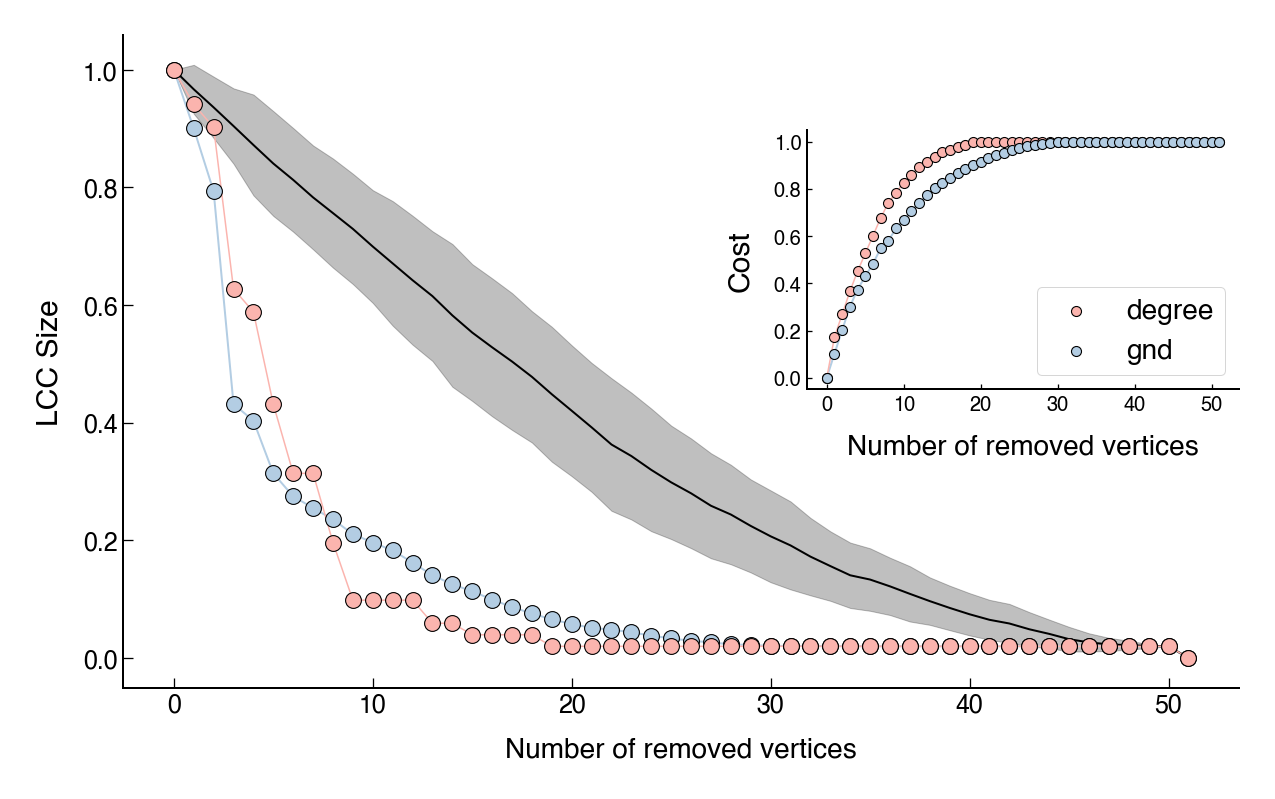
While both methods are better than random node removal, the degree-based dismantling seems to work better. However, this comes at a greater cost. As we can see, although the degree-based dismantling outperforms the GND method, the cost is always higher. Interestingly, we have a slightly different scenario for the Juanes network (Figure 4). In this case, the GND cost is still lower, but both aproaches seem to perform equally well.
Overall, these two aproaches can also be useful as baselines. Costs curves from other aproaches could be compared against these two and this comparison may present an additional analysis for further consideration between cost and effectiveness.
Network modeling
Network models represent useful frameworks in which we can study complex real-world networks. Some random graph models and their extensions have been capable of reproducing the evolution and function of real systems and some of their main features. See here a relatively old but essential review of developments in this field.
Looking more closely at these cocaine smuggling networks, they seem to be based on preferential attachment. Some nodes have many connections to other nodes which, in turn, are not very well connected. This is an indication of preferential attachment, a core property of scale-free networks. Although I have not concluded that their distributions are adequately described by power laws, we could try to simulate these networks with a scale-free model.
As a first guess, we could try using the well-known Barabási–Albert model, since it is also able to generate networks with negative assortativity, low average clustering and low density. In this model, a network of size $n$ is grown by attaching new nodes each with $m$ edges that are preferentially attached to existing nodes with a high degree. However, if $m = 1$ the model networks have clustering coefficients equal to zero, but in the smuggling networks this coefficient is nonzero. We can try setting $m = 2$, but the graphs would (at least visually) clearly differ from the empirical networks. Click here to see an example of this model for three different values of $m$.
After doing some research, I found a version of the barabasi model called dual Barabási–Albert model (DBA), implemented in NetworkX. This model has two parameters that control the attachment probabilities of new nodes, described as follows. A graph of $n$ nodes is grown by attaching new nodes each with either $m_1$ edges (with probability $p$) or $m_2$ edges (with probability $1-p$), which are preferentially attached to existing nodes with a high degree. Moreover, as the authors of the paper explain, “the DBA model is not guaranteed to (and will likely not) yield power-law degree distributions”. Therefore, our ignorance regarding the degree distributions of the empirical networks is not of great concern.
The network below is an example of a random network generated by this model. The visual similarity is surprising. If we look closely, we can see some of the connection patterns seen in the empirical networks.
Random network: A random network ($n = 38$, $m_1 = 1$, $m_2 = 5$ and $p = 0.7$) generated using the dual Barabási–Albert preferential attachment model. The resulting graph has 65 edges.
Of course, this is just one example with specific parameters. We obviously have a lot of room for parameter tuning here. However, in order to obtain the similar pattern of a high degree node connecting to many other nodes that themselves have just one connection, either $m_1$ or $m_2$ must be set equal to 1. The other parameters ($m_2$ and $p$) were chosen arbitrarily.
Naturally, we can examine whether the model networks also produce similar properties to those calculated for the empirical ones. The following values are averages, for every metric, of 1,000 networks grown using the model. Each one of these has the same size as the empirical smuggling networks. Also, in all calculations, I have set $m_1 = 1$, $m_2 = 5$ and $p = 0.7$ fixed. Ultimately, I could vary these parameters and possibly get better results by tuning them. However, as we can see below, the results are already pretty good.
Click to show the density
smuggling_networks_density
0.125 # Mambo
0.130 # Model
0.123 # Acero
0.156 # Model
0.071 # Jake
0.110 # Model
0.073 # Juanes
0.081 # Model
Click to show the assortativity
smuggling_networks_assortativity
-0.088 # Mambo
-0.090 # Model
-0.160 # Acero
-0.108 # Model
-0.173 # Jake
-0.082 # Model
-0.081 # Juanes
-0.067 # Model
Click to show average clustering
smuggling_networks_average_clustering
0.442 # Mambo
0.207 # Model
0.268 # Acero
0.240 # Model
0.110 # Jake
0.180 # Model
0.364 # Juanes
0.151 # Model
Click to show network efficiency
smuggling_networks_global_efficiency
0.473 # Mambo
0.473 # Model
0.481 # Acero
0.500 # Model
0.420 # Jake
0.425 # Model
0.373 # Juanes
0.424 # Model
Click to show average shortest path
smuggling_networks_average_shortest_path
2.473 # Mambo
2.479 # Model
2.413 # Acero
2.372 # Model
2.705 # Jake
2.601 # Model
3.308 # Juanes
2.740 # Model
Click to show the pseudo network diameter
smuggling_networks_global_efficiency
4.0 # Mambo
4.9 # Model
5.0 # Acero
4.7 # Model
4.0 # Jake
5.2 # Model
7.0 # Juanes
5.6 # Model
Obviously, even though the metrics are quite close, matching only six coefficients and a visual aspect is not enough to conclude that this model is an appropriate fit for smuggling networks. Also, we must remember that we only have four networks of this type. When more data of this type are available, we may be able to better support or refute this idea.
What’s next?
I also performed a link prediction analysis using Node2Vec and a Random Forest Classifier. Since there is no information about the evolution of these networks over time, I tried to recreate a graph that might have existed at a previous point in time. To do this, I removed some links that would not completely affect the structure of the graphs. This gave me two snapshots of the networks and allowed me to test the link prediction. In the end, I got an AUC score greater than $0.7$ for all networks. I have not completed this analysis yet, so I may post the details in the future.
-
The GND method uses a cascading approach for dismantling a network, meaning that measurements are updated after each deletion. For this reason, the same procedure was applied for the removal of the nodes with the highest degrees. The alternative approach, where the nodes to be removed are obtained only once, is known as simultaneous attack. ↩︎